링크 : darknet pretrained weights with MS-COCO detection dataset
틈틈히 작업하던 yolo to pytorch가 완성단계라 위 링크 weights들의 정확도를 재생산하는 것을 통해 검증하려고 하는데 validationset에 대한 결과가 이상하리만큼 높게 나오는 것을 발견했다.
yolov4 같은 겨우 width=608 height=608 in cfg: 65.7% mAP@0.5 (43.5% AP@0.5:0.95) 라고 적혀 있는데 (testset기준)
coco 2017 validationset(5k)로 직접 evaluation 했더니
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.500
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.741
이 나왔다. 위 결과는 testset(40k)일테니 낮은건 이해하지만 유난히 높게 나왔다는 생각이 들어 조금 알아봤다.
왜 유난히 높다라는 생각이 들었냐면, 후속논문인 sclaed yolov4 에서 validationset을 통해 측정을 한 결과가 다음과 같다. yolov4-P5경우 896x896 이미지를 사용했는데 51.7 / 70.3 (아래 테이블 참조)이다. 따라서 위에서 yolov4로 돌린 결과가 이상하다고 볼 수 있다.

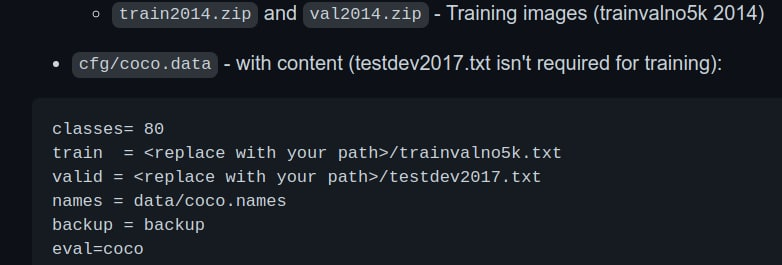
첫번째로 yolov4를 학습할 때, validationset이 포함됐나?를 떠올렸다. 그러면 높은 결과가 이해가 되니까.
그러나 darknet 위키를 찾은결과 학습에는 분명히 validation 5k를 제외하고 학습이 되었다. 정말 이상해서 더 자료를 찾다가 원하는 내용의 issue를 찾았다.
The custom splits (trainvalno5k.txt and 5k.txt) for COCO 2014 are supposed to be the same as the default splits for COCO 2017 but they are not. This could explain why YOLOv4 does not produce the same validation results on both but a significantly better mAP on val2017. Also, this implies YOLO may be trained on a different training set compared with other object detectors. Then a direct comparison might not be fair. Any clarifications?
즉 coco2017과 darknet에서 쓰는 split (train, val, test)가 다르다. 이것은 trainset이 다르단 소리고 결과가 불공정하지않냐? 라는 질문이다.
그러면서 coco2014와 2017의 차이점도 친절하게 official에서 긁어놨다.
The only difference is the splits which COCO 2017 adopts as the long-ime convention from COCO 2014 in early object detection work. The detectron repo explicitly describes the COCO Minival Annotations (5k) as follows:
Our custom minival and valminusminival annotations are available for download here. Please note that minival is exactly equivalent to the recently defined 2017 val set. Similarly, the union of valminusminival and the 2014 train is exactly equivalent to the 2017 train set.
즉 2014와 2017은 이미지가 전혀 바뀐게 없고 split만 바꼈다는 것인데 다음과 같다. (valminusminival의 존재를 처음 앎;)
COCO_2017_train = COCO_2014_train + valminusminival
COCO_2017_val = minival
거기에 대한 답은 이렇다.
- testset은 같다.
- validation이 다르지만 결국엔 똑같은 장수를 validation으로 뺐고 test는 같으니 결과는 문제없다!.
심지어 우리는 최종 weight에 5k를 빼고학습했으니 오히려 마이너스 요소가 될 수 있다. 가 답변이다.
왜 다른 split을 쓰는지는 나도 모르겠지만, test로 성능측정하려면 서버에 결과제출해야해서 귀찮은데..하 아무튼 이런 이슈가 존재한다.
'Deep Learning > 기타' 카테고리의 다른 글
| [Dataset] NIH Google (0) | 2024.05.24 |
|---|---|
| vscode에서 서버 연결할 때, XHR failed (0) | 2021.08.26 |
| coco label items (0) | 2021.08.11 |