개인적으로 읽고 쓰는 공부용 리뷰입니다.
틀린 점이 있을 수도 있으니 감안하고 읽어주세요. 피드백은 댓글로 부탁드립니다.
paper overview
- 논문링크 : paper link
- CVPR 2022
- convnet + transfomer
- cnn과 transformer의 장점을 적절히 섞으면서 성능향상을 이끌어 냄
Abstract
transformer가 대부분의 downstream task에서 sota찍고 날라다니지만 CNN 아직 죽지않았다. 심폐소생술 가능하다. 보여주겠다.
1. Introduction
- CNN은 “sliding window” 전략을 택한다.
- VIT의 주요한 포인트는 큰 데이터와 큰 모델의 "scaling"
- 이 둘을 잘 조합한게 swin transformer
- convolution의 본질은 여전히 살아있으며 아직도 중요하다.
The essence of convolution is not becoming irrelevant; rather, it remains much desired and has never faded.
- 이를 증명하기 위해서 resnet에 transfomer의 특징을 하나씩 적용해가며 성능을 끌어올린다.
How do design decisions in Transformers impact ConvNets’ performance?
2. Modernizing a ConvNet: a Roadmap
 |
사실 상 이 그림이 이 논문의 전부를 표현함. 일단 x축은 imagenet 성능을 나타내고 y축은 적용한 방법이다. 남색 막대는 resnet50의 성능이고 회색바는 resnet200의 성능이다. 별은 resnet50의 GFLOPs를 의미한다. 조금 더 부연설명하자면 vanilla resnet50의 성능은 78.8이고 여기에 stage ratio 를 적용했을 때, 79.4로 성능향상 0.4GFLOPs 증가인 것이다. 거기에 추가로 patchify stem을 적용했을 때 추가로 79.5까지 성능이 증가된 것이다. 빗금 쳐진 Kernel size 9, 11은 채택되지 않은 방법을 의미한다. 논문의 나머지는 이제부터 78.8에서 82.0까지 성능을 끌어올린 각각의 세부 기법들에 대해서 설명한다. |
2.1. Training Techniques
 |
사실 resnet이 처음 나왔을 때에 비해 현재는 많은 학습 방법들이 생겨났다. optimizer, scheduler, augmentation 등등. 그렇기 때문에 초기 resnet에 단순히 최신 학습 기법들만 적용해도 성능은 향상할 것이다. 왼쪽 table처럼 학습을 했을 때 모델은 기존 성능은 76.1에서 78.8로 향상한다. ConvNeXt모델은 여기서부터 시작한다. |
2.2. Macro Design
Changing stage compute ratio : resnet의 기존 convbolck 구조 (3,4,6,3)에서 swin transformer처럼 (3,3,9,3)으로 바꿨더니 79.4로 성능 향상. ( Swin-T, on the other hand, followed the same principle but with a slightly different stage compute ratio of 1:1:3:1)
Changing stem to “Patchify” : Resnet은 처음에 7by7 conv with s=2 적용하고 maxpool 때려서 초기에 1/4로 featuremap 크기를 줄이는데 이 방식을 transformer의 patch 처럼 바꿔서 적용한다. ( We replace the ResNet-style stem cell with a patchify layer implemented using a 4×4, stride 4 convolutional layer. ) 성능은 79.5로 향상
2.3. ResNeXt-ify
- Resnet을 ResNeXt처럼 변경. depthwise conv와 3x3 group conv 적용. ( ResNeXt employs grouped convolution for the 3×3 conv layer in a bottleneck block. Depthwise conv is similar to the weighted sum operation in self-attention. )
- SwinTransformer와 같은 width를 가지도록 채널을 96으로 증가 ( we increase the network width to the same number of channels as Swin-T’s (from 64 to 96). )
- 성능은 80.5로 향상
2.4. Inverted Bottleneck
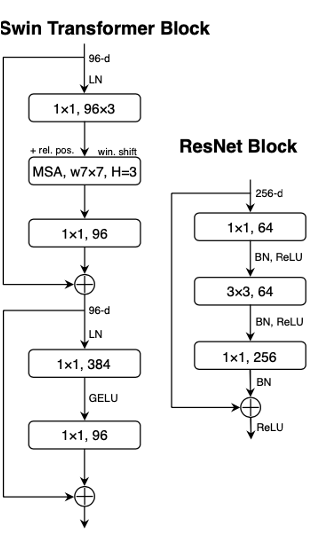 |
 (a) is a ResNeXt block
(b) is an inverted bottleneck block
|
- Transformer block is that it creates an inverted bottleneck. MLP block is four times wider than the input dimension.
- depthwise conv에서 연산량이 증가하긴 하지만 downsampling convlayer에서 연산량이 많이 줄어들어서 전체 연산량은 줄어들었음.
- 성능은 80.5에서 80.6으로 향상
2.5. Large Kernel Sizes
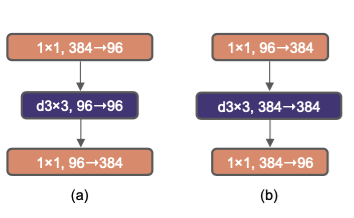
| Moving up depthwise conv layer | |
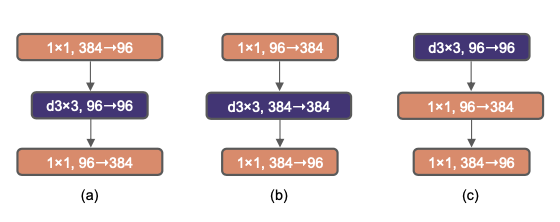 |
아까 b처럼 바꿨던 부분을 transformer처럼 3by3 conv부분을 위로 올려서 적용. 당연히 연산량도 엄청 줄어들고 성능도 79.9로 감소 |
Increasing the kernel size : conv layer를 위로 올려서 생긴 연산량 및 성능 감소를 보완하기 위해 3by3대신 보다 큰 kernel을 사용 5~11까지 사용해봤는데 7by7 conv를 적용했을 때 80.6으로 연산량과 성능에서 제일 좋았음. -> 7by7 선택
2.6. Micro Design
| Replacing ReLU with GELU | ||
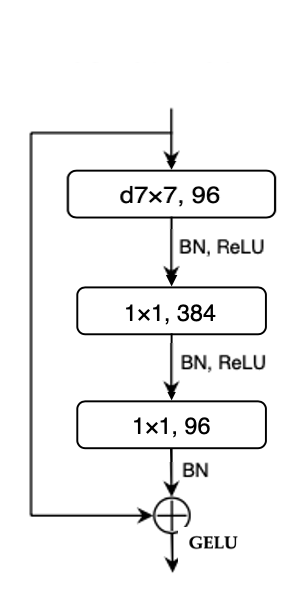 |
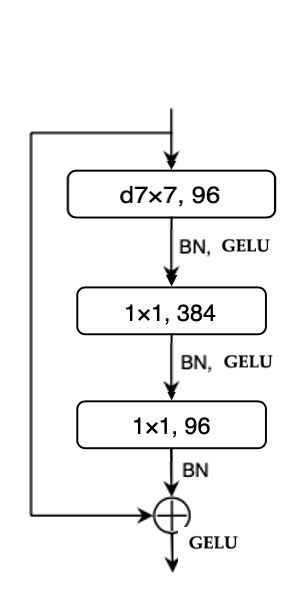 |
왼쪽 그림처럼 ReLU가 사용 되는 부분을 GELU로 변경. GELU는 다양한 transformer에서 사용 됨 GELU, which can be thought of as a smoother variant of ReLU, is utilized in the most advanced Transformers, including BERT and GPT-2 and, most recently, ViTs. 성능은 똑같이 80.6 |
Fewer activation functions
 |
Transformers have fewer activation functions compared to ResNet. There is only one activation function present in the MLP block. transformer는 MLP block내에서 하나의 활성화 함수만 가지기 때문에 이것도 똑같이 처리함. 성능은 81.3으로 향상. ( 이 부분이 많은 성능 향상을 가져왔는데 분석이 없어서 아쉬움. ) |
Fewer normalization layers : transformer block은 activation 함수처럼 normalization layer도 1개만 갖기 때문에 맨위 BN 빼고 아래 두 BN을 삭제. 성능은 81.4로 향상.
Substituting BN with LN : 마찬가지로 transformer block은 LN을 사용하기 때문에 1개 남은 BN을 LN으로 교체. 81.5로 성능 향상
Separate downsampling layers : resnet은 downsampling을 3x3 layer에서 stride 높여서 처리했는데, swin은 이부분을 나눠서 처리함. 이처럼 똑같이 독립시켜서 적용함. ( we use 2×2 conv layers with stride 2 for spatial downsampling. This modification surprisingly leads to diverged training. Adding normalization layers at spatial resolution changes aids in training stability. ) 성능은 82.0으로 향상
이로써 최종적으로, 타겟팅한 swin transformer의 성능을 따라잡음. model scaling도 마찬가지로 resnet 200이 swin base의 성능을 뛰어 넘음.
이 뒤의 내용은 실험부분이고 주목할만한 부분은 없어서 스킵.